其实测试这种分布式系统意义不是非常大,因为通过监控metric发现性能瓶时,直接增加节点即可,在很大范围内,节点数不是非常多的话,基本上处理能力呈线形增长,直接引用源作者的话:
“High performance and linear scalability up to 1000 nodes. There are no proxies, asynchronous replication is used, and no merge operations are performed on values.”
但是为什么要做一个简单的性能测试,因为第一次部署redis cluster,到底部署什么样的规模才能满足需求是无法回避的问题。所以还是简单测试下,为什么称为简单测试,因为实际环境中的软硬件配置、实际应用操作的读写比例、读写内容大小、读写波动范围、读写的机器数、线程数等实际场景,远不是本地可以简单真实模拟的。所以这里只是简单测试下(关注点在速度),以有个感性的认识,以回答部署需要什么样的规模等问题。
127.0.0.1:7001>cluster nodes 87903653548352f6c3fdc0fa1ad9fc68de147fcd 10.224.2.142:7001 myself,slave 798f74b21c15120517d44bacfc7b5319b484244b 0 0 2 connected 3892d1dfa68d9976ce44b19e532d9c0e80a0357d 10.224.2.141:7001 slave b2b98976dfbc9f85bf714b385e508b3441c51338 0 1517983027812 17 connected 798f74b21c15120517d44bacfc7b5319b484244b 10.224.2.145:7001 master - 0 1517983028313 5 connected 5461-10922 b2b98976dfbc9f85bf714b385e508b3441c51338 10.224.2.144:7001 master - 0 1517983027813 17 connected 10923-16383 b71b412857c43e05a32a796fbc0de2e7d667cb67 10.224.2.143:7001 slave 912a1efa1f4085b4b7333706e546f64d16580761 0 1517983026306 6 connected 912a1efa1f4085b4b7333706e546f64d16580761 10.224.2.146:7001 master - 0 1517983026809 6 connected 0-5460
| Redis Cluster | Node number | Mini Redis cluster (6 nodes: 3*2 ) | ||
| Configure | Hardware | Cpu: 2 * Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
Memory: 4G(3924392) |
||
| Software | #disable save cache content to disk save “” appendonly no# memory limit maxmemory 1G maxmemory-policy allkeys-lru |
make sure never reach max memroy | ||
| Test Machine | Node number | 15 | ||
| Configure | Hardware configures | Cpu: 2 * Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
Memory: 8G(8180636) |
||
| Software configures | Jedis connection pool :
DEFAULT_MAX_TOTAL = 8 |
|||
| Test method | Operation | write | Test1: 10(machine) * 50(thread per machine) * 20K(write operation)= 10000K
Test2: 15(machine) * 50(thread per machine) * 20K(write operation)= 15000K |
String set(final String key, final String value)(1) key size: about 30
(2) value: size: about 30 |
| read | Test1: 10(machine) * 50(thread per machine) * 20K( read operation)= 10000K. data base existed 10000K records
Test2: 15(machine) * 50(thread per machine) * 20K( read operation)= 15000K, data base exixted 15000K records |
String get(final String key)
(1) no hit (2) key size:about 30 |
||
| Test result | OPS | Read | 100K | |
| Write | 50K | |||
| Success Ratio | Read | 100% | ||
| Write | 100% | |||
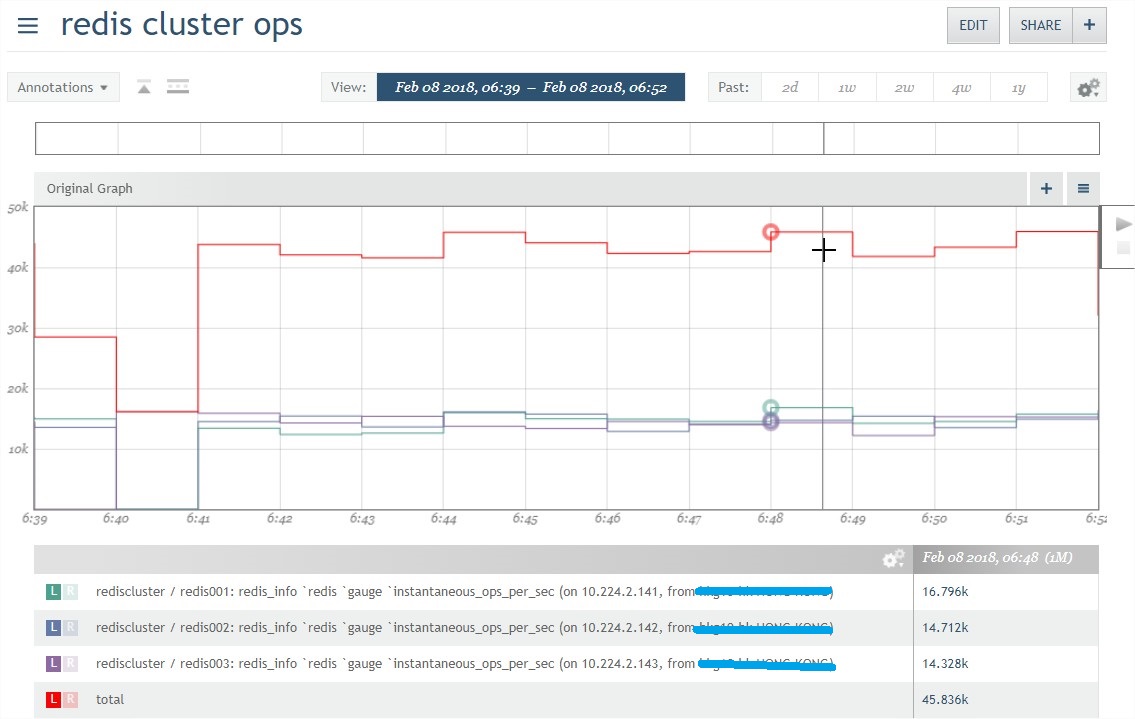
通过下图可知:测试中的key分布比较均匀,所有的压力平坦到3个master中,虽然测试的总tps很高,但是由于三个人干活,导致每个节点其实也还好,凸显分布式优点。

测试结论: redis cluster的最小集(3*2),单纯考虑速度,不考虑容量限制,已经能支持很高TPS的需求了,另外需要注意的事,这是理想的测试,所以实际评估中仅供参考。
题外: 将读写测试1:1混合,会怎样,将两种测试同时并发执行,还能达到10万/S读,5万每S写么?测试结果如下:
总的OPS,只能达到45Kops, 然后读写吞吐量基本差不多1:1。这种数据比单纯只测一种更具有实际参考价值。
 Code
Code