掌握metric基本技术生成metric原始数据后,接下来考虑的问题是:如何绘图和绘制哪些基本的图。
实际上现在一些metric方案,已经不需要考虑这个问题了,例如Metricbeat的方案,导出数据到elastic search后,所有的图形可以一次性执行一个命令(./metricbeat setup –dashboards)来绘制完,不仅包含主机层面的图,也包含常见的流行服务(redis/apache/nginx)的图像:
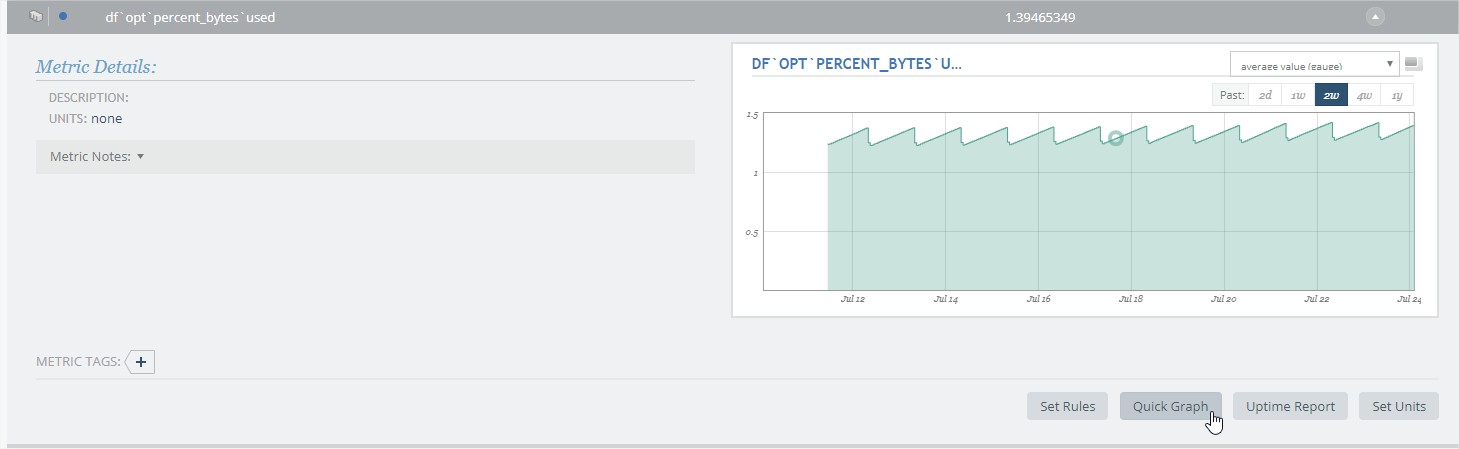
再如使用circonus,每个收集到的数据都可以预览,也可以直接使用“quick graph”功能立即绘制存储。
但是假设使用的metric展示系统不能自动绘制,或者自动绘制的不满足需求,这仍然需要考虑绘制的问题,首先要自问的是,不管是什么应用,我们都需要绘制哪些图?
一 系统层面
(1)CPU
CPU指标可以划分为整机CPU和具体应用(进程)的CPU,当整机CPU过高时,可以通过先定位进程后定位线程的方式来定位问题。同时CPU的指标数值有很多,例如下面的一些指标,所以很多metric系统提供的所有数据的采集,而对于cpu利用率的计算需要自己去计算。
[root@vm001~]# top
top – 23:52:07 up 22:11, 1 user, load average: 0.01, 0.00, 0.00
Tasks: 116 total, 1 running, 115 sleeping, 0 stopped, 0 zombie
Cpu(s): 1.7%us, 0.6%sy, 0.0%ni, 97.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
(2)Load
系统load更能真实反映整个系统的情况,根据统计的时间范围,可以划分为下面示例中的三种:最近1、5、10分钟。一般系统load过高时,CPU不定很高,可能是磁盘存在瓶颈等问题,所以还需要具体问题具体分析。
[root@vm001~]# sar -q
10:40:01 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
10:50:01 PM 4 332 0.04 0.02 0.01
(3)Disk
Disk主要关注两个方面:1 磁盘的剩余容量 2 磁盘的影响速度,包括以下一些常用指标:
- “io_time” – time spent doing I/Os (ms). You can treat this metric as a device load percentage (Value of 1 sec time spent matches 100% of load).
- “weighted_io_time” – measure of both I/O completion time and the backlog that may be accumulating.
- “pending_operations” – shows queue size of pending I/O operations.
(4)Network
Network常见的指标包括建立的tcp连接数目、每秒传输(input/output)的字节数、传输错误发生次数等。
(5)Memory
memory主要包括以下指标,需要注意的是linux系统中,可用的内存不仅指free, 因为linux内存管理的原则是,一旦使用,尽量占用,直到其他应用需要才释放。
[root@vm001 ~]# free -m
total used free shared buffers cached
Mem: 3925 1648 2276 2 248 312
-/+ buffers/cache: 1087 2837
Swap: 3983 0 3983
其中系统层面,还可以将jvm这层纳入到这层里面,例如使用绘制出jmx观察到的所有的jvm的一些关键信息。
二 应用层面
(1) TPS:了解当前的TPS,并判断是否超过系统最大可承载的TPS.
(2)ResponseTime: 获取response time的数据分布,然后排除较长时间的原因,决策是否合并,假设有需要,做合适优化。
(3)Success Ratio :找出所有失败的case,并逐一排查原因,消灭bug或者不合理的地方。
(4)Total Count:有个总体的认识,知道每种api的调用次数和用量分布。
三 用户层面
(1)谁用的最多?
(2)用的最多的业务是什么?
(3)业务的趋势是什么?
除了上面提到的一些基本图表外,我们还可以绘制更多“有趣”图表做更多的事情:
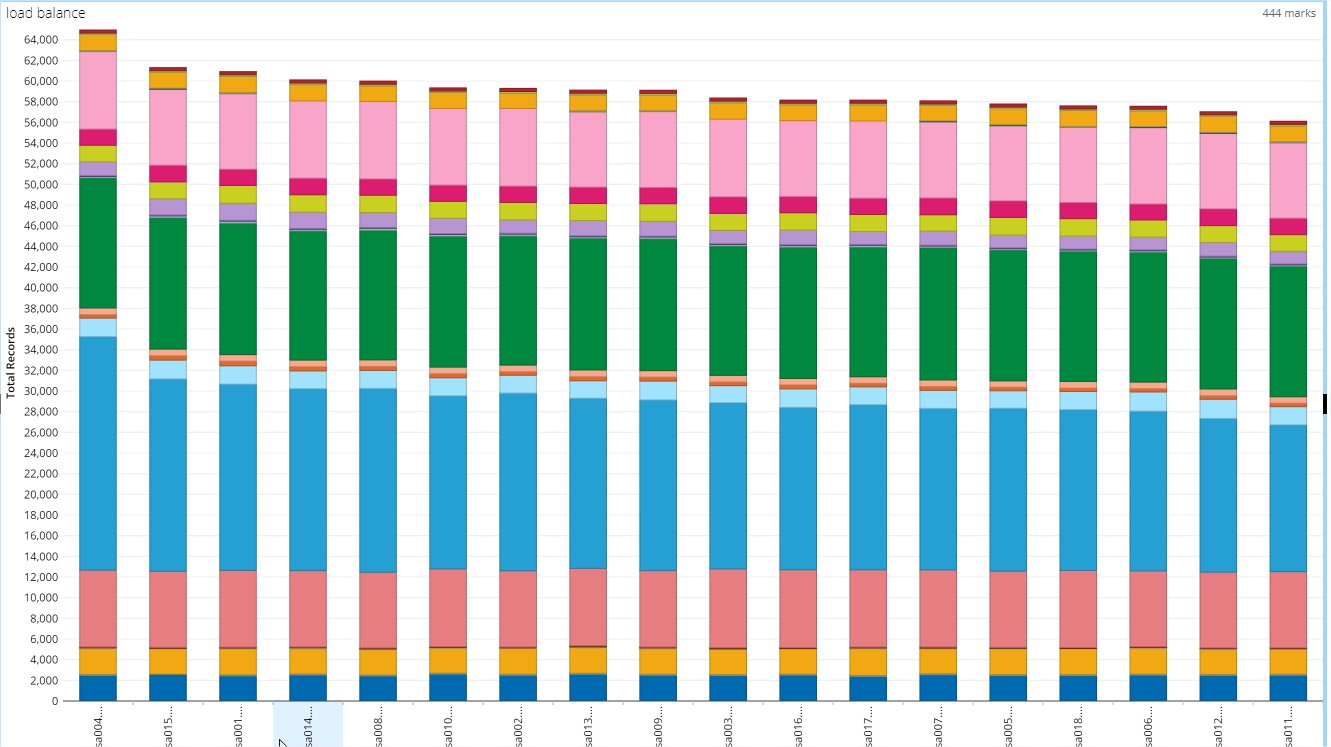
(1) load balance是否均衡
X为主机名,Y为请求总数,不同颜色表示不同类型的请求。
(2) 是否可以安全的淘汰一个接口或者功能:
淘汰一个api或者功能时,很多现实是预期之外的,例如应用多个版本的存在、运维的原因都可能导致仍然有“用量”,所以最安全的方式是实际统计使用情况来决定淘汰的时机。例如下图是某个api的调用次数。可见用量逐渐趋向于0,从8月21号,可以删除这个接口或者功能了。

(3) 预警“入侵”
可以通过变化率来判断是否有入侵存在,正常的峰值及变化率会稳定在一定的范围,但是如果变化率极高,这可能是入侵,应予以预警。如下图,在5月30号,出现极其高的访问量,实际上入侵的发生导致。

(4)预警硬件故障。
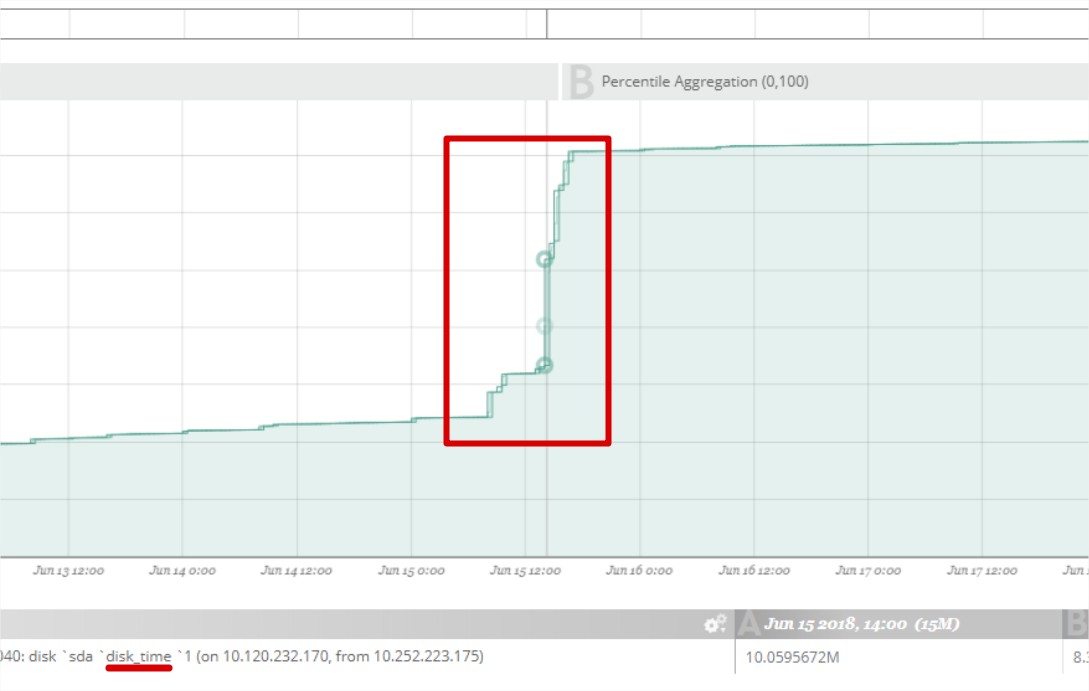
一些硬件的可以,也可以通过metric监控到,例如常见的磁盘问题,磁盘一般在彻底损坏之前,都是先出现‘慢’的特征,所以在彻底坏之前,通过磁盘的disk time来判断趋势和变化,也能在彻底损坏前,更换磁盘,例如下面的图中,15号后磁盘的disk time陡增。
除了以上一些用法,还有其他一些,例如对某个场景是否发生和发生频率感兴趣,所以记录metric来统计发生的概率,诸如此类,有了数据后,可以做很多有趣的事情。
参考文献:
1 https://collectd.org/wiki/index.php/Plugin:Disk
2 https://collectd.org/wiki/index.php/Plugin:Memory