上篇文章枚举了诸多互联网公司分享的应用redis cluster中遇到的问题,本文罗列所在公司上线后出现的一些问题,也包括一些小的困惑。
问题1:出现auto failover
现象:监控redis半个多月的时候,偶然发现其中1台master自动触发failover。
原因:
1.1 查看出现的时间点的日志:
Node 912a1efa1f4085b4b7333706e546f64d16580761 reported node 3892d1dfa68d9976ce44b19e532d9c0e80a0357d as not reachable.
从日志看到node not reachable,首先想到2个因素:
(1)redis是单进程和单线程,所以有任何一个耗时操作都会导致阻塞时间过长,最终导致failover.
(2)网络因素;
首先排除了可能原因(1),因为从系统应用分析,并无任何特殊操作。都是最普通的操作且请求量很小,可能原因(2)不能排除。
1.2 查看出现问题时间点的系统资源应用情况:
查看了所有的常见指标,除了最近1分钟的load异常外,均正常,锁定原因为:系统load过高,达到7,导致系统僵死。其他节点认为这个节点挂了。
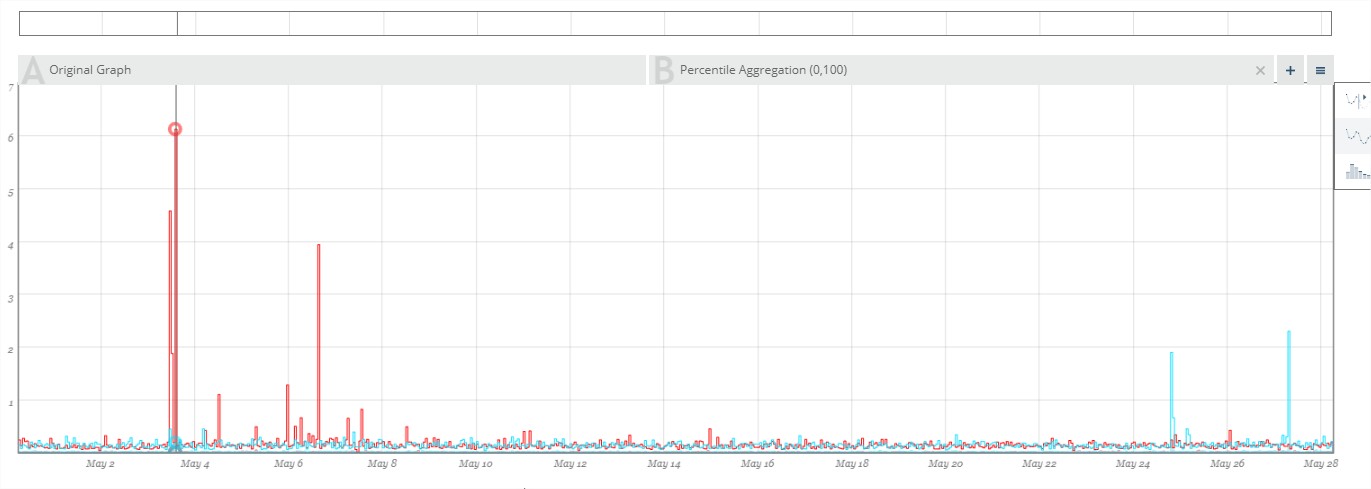
解决:考虑到所有其他指标:cpu/memory/disk等都正常,以及其他2台master一直也正常,业务量非常小,这种情况偶发,所以归结问题原因是这台虚拟机有问题,所以反馈问题并迁移虚拟机,迁移后system load一直平稳无问题。也没有出现failover.
困惑2:slave的ops远小于master的ops
现象:已知所有操作都是删除操作,并无查询操作。所以很好奇,为什么master和slave的ops差别这么大:前3台为master,达到100ops,相反slave不到10.

解惑:CRUD中,不见得只要是CUD就肯定会“传播”命令到slave,还有一个条件是必须“库”发生了改变。例如当前的业务中,处于测试阶段,所有主流操作都是删除操作,而且这些删除操作都是删除一个没有key的操作。所以并没有发生改变(即下文中dirty为0)。
计算dirty值:
/* Call the command. */
c->flags &= ~(REDIS_FORCE_AOF|REDIS_FORCE_REPL);
// 保留旧 dirty 计数器值
dirty = server.dirty;
// 计算命令开始执行的时间
start = ustime();
// 执行实现函数
c->cmd->proc(c);
// 计算命令执行耗费的时间
duration = ustime()-start;
// 计算命令执行之后的 dirty 值
dirty = server.dirty-dirty;
只有dirty值发生改变:
// 如果数据库有被修改,即判断dirty,那么启用 REPL 和 AOF 传播
if (dirty)
flags |= (REDIS_PROPAGATE_REPL | REDIS_PROPAGATE_AOF);
if (flags != REDIS_PROPAGATE_NONE)
propagate(c->cmd,c->db->id,c->argv,c->argc,flags);
所有的操作,不见得都会改变dirty值:
void delCommand(redisClient *c) {
int deleted = 0, j;
for (j = 1; j < c->argc; j++) {
// 尝试删除键
if (dbDelete(c->db,c->argv[j])) {
//改变server.dirty
server.dirty++;
}
}
}
问题3:socket timeout
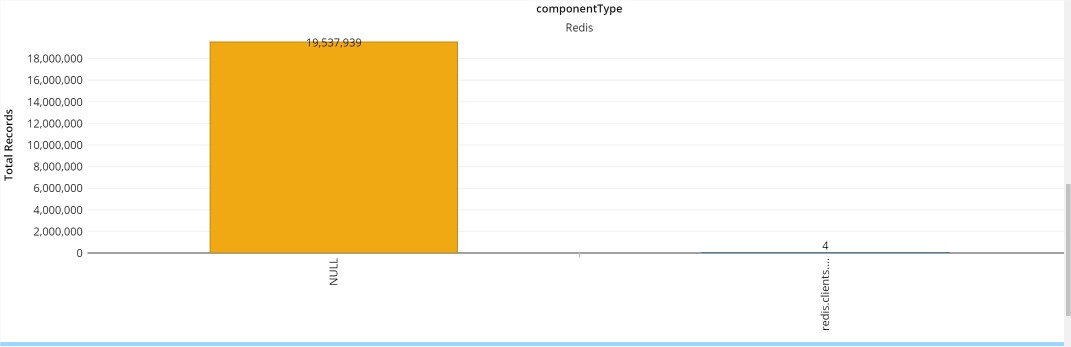
现象:查看最近1周数据访问量,有4个socket timeout错误:
redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: Read timed out at redis.clients.util.RedisInputStream.ensureFill(RedisInputStream.java:202) at redis.clients.util.RedisInputStream.readByte(RedisInputStream.java:40) at redis.clients.jedis.Protocol.process(Protocol.java:151) at redis.clients.jedis.Protocol.read(Protocol.java:215) at redis.clients.jedis.Connection.readProtocolWithCheckingBroken(Connection.java:340) at redis.clients.jedis.Connection.getIntegerReply(Connection.java:265) at redis.clients.jedis.Jedis.del(Jedis.java:197) at redis.clients.jedis.JedisCluster$110.execute(JedisCluster.java:1205) at redis.clients.jedis.JedisCluster$110.execute(JedisCluster.java:1202) at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:120) at redis.clients.jedis.JedisClusterCommand.run(JedisClusterCommand.java:31) at redis.clients.jedis.JedisCluster.del(JedisCluster.java:1207) at com.webex.dsagent.client.redis.RedisClientImpl.deleteSelectedTelephonyPoolsInfo(RedisClientImpl.java:77) at sun.reflect.GeneratedMethodAccessor75.invoke(Unknown Source)
配置: connectionTimeout=800 soTimeout=1000 BTW: 确实消耗了>1000ms componentType":"Redis","totalDurationInMS":1163
原因: 查看4个错误发生的时间,都发生在某天的一个时间点,且用key计算分段,也处于同一个机器上,所以归结到网络原因或虚拟机问题,无法重现。