再次遇到NoHostAvailableException,诡异的是:检查了下Cassandra的节点,又都是Up状态,和之前遇到的情况如出一辙。
所以有必要关于这个异常做个记录,汇总下两次遇到这种情况的原因:
继续阅读about Cassandra “NoHostAvailableException” when all host available
再次遇到NoHostAvailableException,诡异的是:检查了下Cassandra的节点,又都是Up状态,和之前遇到的情况如出一辙。
所以有必要关于这个异常做个记录,汇总下两次遇到这种情况的原因:
继续阅读about Cassandra “NoHostAvailableException” when all host available
通过Cassandra Driver来执行一段CQL有很多方式,每种方式的适用场景和性能不尽相同,所以一定要明确各种方式区别并合理选择才能最优化性能,通过代码阅读,可以归纳出以下几种方式:
例如:
com.datastax.driver.core.AbstractSession.execute(String) com.datastax.driver.core.AbstractSession.executeAsync(String)
区别在于:是否等待返回结果。
executeAsync(statement).getUninterruptibly();//getUninterruptibly is waiting response
对于不需要结果、异步处理的数据操作完全可以用异步方式来执行,很明显能否提高效率。
在使用上,必须先将要执行的CQL进行prepare,然后根据prepare的结果PreparedStatement创建BoundStatement然后执行,换言之:无法不进行prepare而直接使用BoundStatement(因为其仅有一个以PreparedStatement 为参数的构造器)
PreparedStatement statement=connect.prepare("insert into site(siteid,activeid) values (?,?)");
connect.execute(new BoundStatement(statement2).bind(12111l,12111l)) //style one
connect.execute(statement.bind(12111l,12111l)) //style two
对于任何一个cql的执行,cassandra要分成两大基本步骤:prepare(代码如下所示)和执行,其中prepare会做解析语句、基本的语法检查等他准备工作,所以对于仅仅是参数不同的相同语法的CQL而言,prepare是重复多余的,所以有了prepare语句的概念,即对于经常执行的相同语法、不同参数的CQL可以预先prepare一次,以后不用在prepare。 通过下面的代码调用图示,比较普通Query(QueryMessage)和已Prepare的Query(即Bound statement: 消息类型为ExecuteMessage)可知区别在于是否含有示例代码: 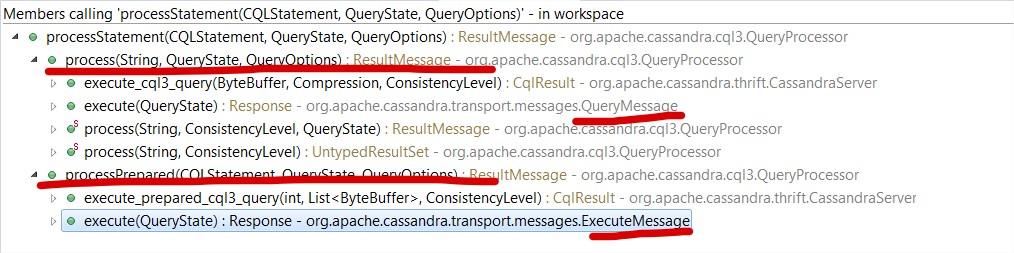
public static ParsedStatement.Prepared getStatement(String queryStr, ClientState clientState)
throws RequestValidationException
{
Tracing.trace("Parsing {}", queryStr);
ParsedStatement statement = parseStatement(queryStr);
// Set keyspace for statement that require login
if (statement instanceof CFStatement)
((CFStatement)statement).prepareKeyspace(clientState);
Tracing.trace("Preparing statement");
return statement.prepare();
}
从实现上,大体是先将prepare statement请求以statementid为Key存储一份Prepared 的Map数据,以后接受到bound statement的语句时,直接根据statementId来获取。如果找不到存储的数据,抛出提示“事先没有Prepare”的。
ParsedStatement.Prepared prepared = handler.getPrepared(statementId); if (prepared == null) throw new PreparedQueryNotFoundException(statementId);
对于客户端,首先发出prepare请求时,会根据load balance策略发出一个请求给其中的一个节点,如果成功,则会将prepare请求发送给其他剩余的符合load balance策略的其他所有节点,这样等于说一次prepare会将所有以后可能处理请求的所有结点都prepare下。 同时定义的request type区分了不同的statement:
QUERY (7, Requests.Query //common,can execute batch operations PREPARE (9, Requests.Prepare, //prepare statement EXECUTE (10, Requests.Execute, //Bound statement BATCH (13, Requests.Execute, //Batch statement
通过以下三点的理解,在使用时,我们难免产生一些困惑:
困惑1: prepare的使用要求我们必须先prepare一次,那么假设当时某种因素导致prepare失败,是不是以后重复执行的bound语句都会报错:因为PreparedQueryNotFoundException 解惑: 实际使用中,如果遇到没有prepare的返回,会重试:这里的重试包括2个部分:在返回没有prepare的结点上重新prepare,然后在这个结点上将bound statement请求重新做一篇:
case UNPREPARED: connection.write(prepareAndRetry(toPrepare.getQueryString()));
困惑2: 在一次性prepare之后新加入cassandra node,这个新结点上会做prepare么? 解惑: 只要prepare之后,client都会将它存进一个ConcurrentMap<MD5Digest, PreparedStatement>,然后有新的Node加入时,将曾经prepare过的statement重新做一次(com.datastax.driver.core.Cluster.Manager.onAdd(Host))
困惑3: 如果多prepare了几次,会有什么影响: 解惑: Server端本身会判断是否已在cache中,如果在则不会重新prepare,所以对于server本身影响不会太恶劣,但是对于客户端来说,影响很大,因为每次prepare都会将prepare statement发送给所有符合loadbalance策略的结点。
综上,使用prepare很明显对于重复执行、语法相同、参数不同的CQL具有很高的效益,能避免反复执行的prepare操作: 实测比较prepare和非prepare的trace可以知道,节约了这2步:
Parsing insert into site(siteid) values (1212) on /10.224.57.207[SharedPool-Worker-1] at Wed May 27 16:42:32 CST 2015 Preparing statement on /10.224.57.207[SharedPool-Worker-1] at Wed May 27 16:42:32 CST 2015
batch这种方式很好理解,可以将可以批处理的请求融合到一起,很好的节约带宽,例如需要每笔业务需要写入3个号码(宅电,手机,工作电话等)的场景下就很适合,当然也可以将不同数据操作放在一次请求中做。
同时batch分为三种类型:
public enum Type {
/**
* A logged batch: Cassandra will first write the batch to its distributed batch log
* to ensure the atomicity of the batch.
*/
LOGGED,
/**
* A batch that doesn't use Cassandra's distributed batch log. Such batch are not
* guaranteed to be atomic.
*/
UNLOGGED,
/**
* A counter batch. Note that such batch is the only type that can contain counter
* operations and it can only contain these.
*/
COUNTER
};
按客户端处理的请求类型划分:Query and Batch,分别对应于com.datastax.driver.core.querybuilder.Batch和com.datastax.driver.core.BatchStatement:
前者对应代码组成Query类型:
builder.append(isCounterOp()
? "BEGIN COUNTER BATCH"
: (logged ? "BEGIN BATCH" : "BEGIN UNLOGGED BATCH"));
if (!usings.usings.isEmpty()) {
builder.append(" USING ");
Utils.joinAndAppend(builder, " AND ", usings.usings, variables);
}
builder.append(' ');
for (int i = 0; i < statements.size(); i++) {
RegularStatement stmt = statements.get(i);
if (stmt instanceof BuiltStatement) {
BuiltStatement bst = (BuiltStatement)stmt;
builder.append(maybeAddSemicolon(bst.buildQueryString(variables)));
} else {
String str = stmt.getQueryString();
builder.append(str);
if (!str.trim().endsWith(";"))
builder.append(';');
// Note that we force hasBindMarkers if there is any non-BuiltStatement, so we know
// that we can only get there with variables == null
assert variables == null;
}
}
builder.append("APPLY BATCH;");
return builder;
服务器端接受到2种类型的batch操作,最终复用了batch statement的代码:
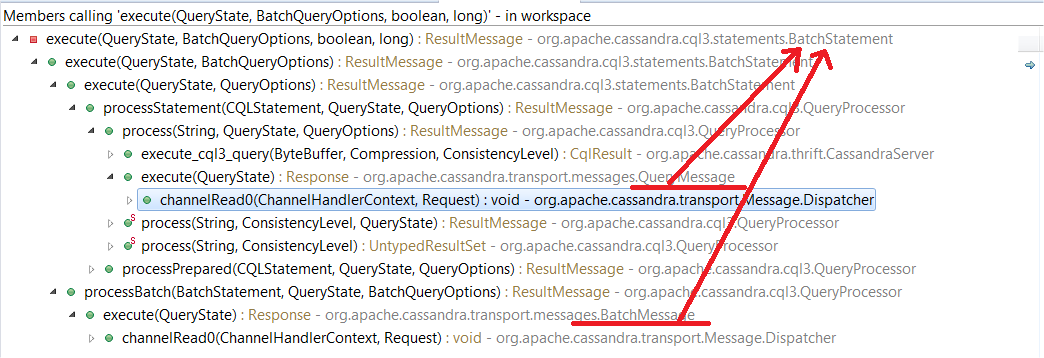
同时batch操作必须符合两大基本要求:
(1)不能混合counter操作和非counter操作;
(2)仅能支持delete/update/insert三种修改操作;
使用风格更多的的是提供语法糖或操作的便捷性:例如对于第一种可以直接书写的CQL可以使用第二种:
public ResultSet execute(String query); public ResultSet execute(String query, Object... values); //session.execute( "INSERT INTO images (image_id, title, bytes) VALUES (?, ?, ?)", imageId, imageTitle, imageBytes ); public ResultSet execute(Statement statement);
这种方式比较简单,所以不做过多解释。
1 根据不同的划分方式可以找出不同的statement,在实际中,可以将多种方式结合起来,例如下面的代码示例: prepare/batch/bound三者结合:其中ps.bind(uid, mid1, title1, body1)返回的是bound statement
PreparedStatement ps = session.prepare("INSERT INTO messages (user_id, msg_id, title, body) VALUES (?, ?, ?, ?)");
BatchStatement batch = new BatchStatement();
batch.add(ps.bind(uid, mid1, title1, body1));
batch.add(ps.bind(uid, mid2, title2, body2));
batch.add(ps.bind(uid, mid3, title3, body3));
session.execute(batch);
2 摒弃不加思考的将某种方式贯彻到底,根据不同应用场合选择不同的方式(例如使用batch/prepare)可以提高效率。