现象:
查看某个host的最近2周的load(last 1 minute)情况,可观察到尖峰时刻发生在5月3号,数值为0.167.
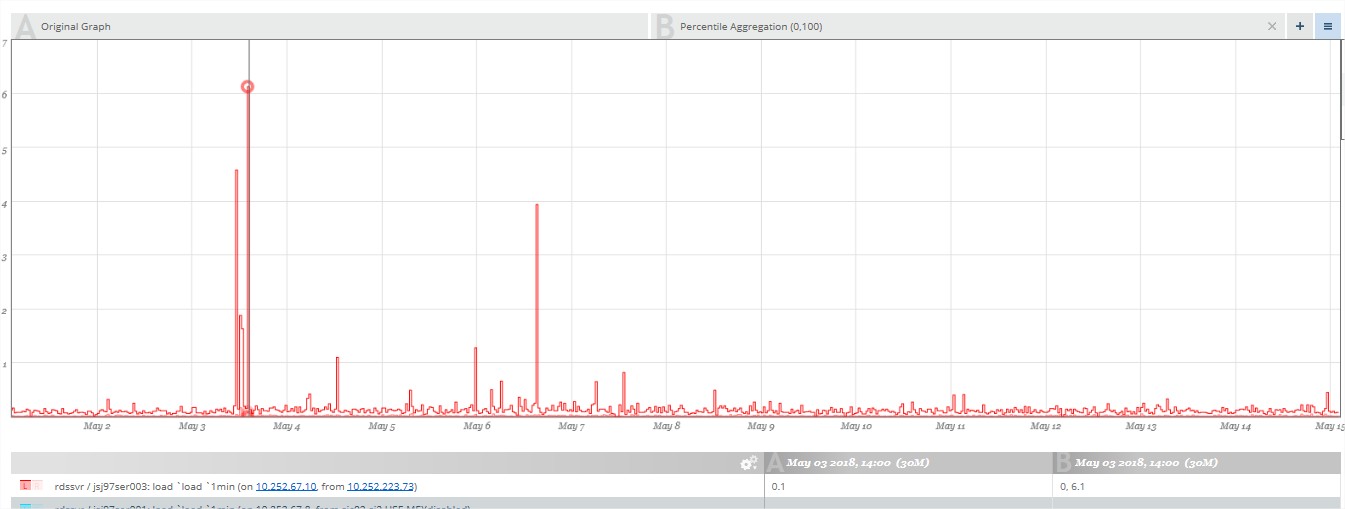
当试图查看具体什么时间点达到尖峰时(缩小时间范围),发现这个尖峰时刻的数据值不再是0.167,而是2:
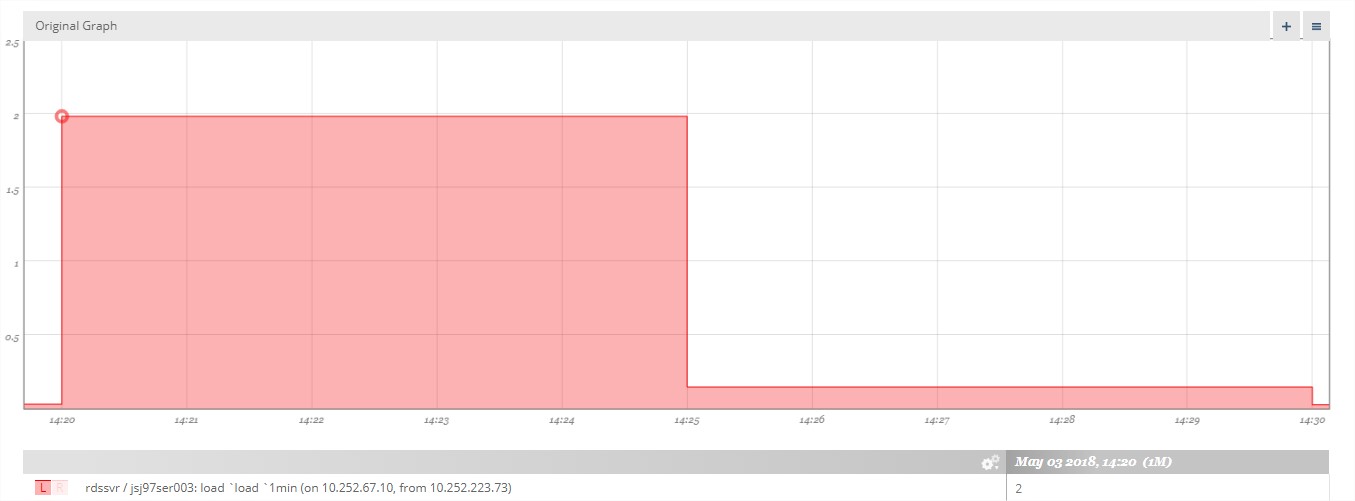
从现象上表明:时间范围越大,数据的可信度越低,继续查看图1中的其他低点的尖峰,缩小时间范围后,竟然超过了第一尖峰,验证了这个设想。
原因:
按常理,绘制图像的时候,直接将所有的数据展示出来即可,简单明了,但是实际操作中,对于一个时间范围较小的数据量较小时,并不存在问题,但是考虑到假设需要展示1年或者一个数据量超级大的数据时,存在两个问题:
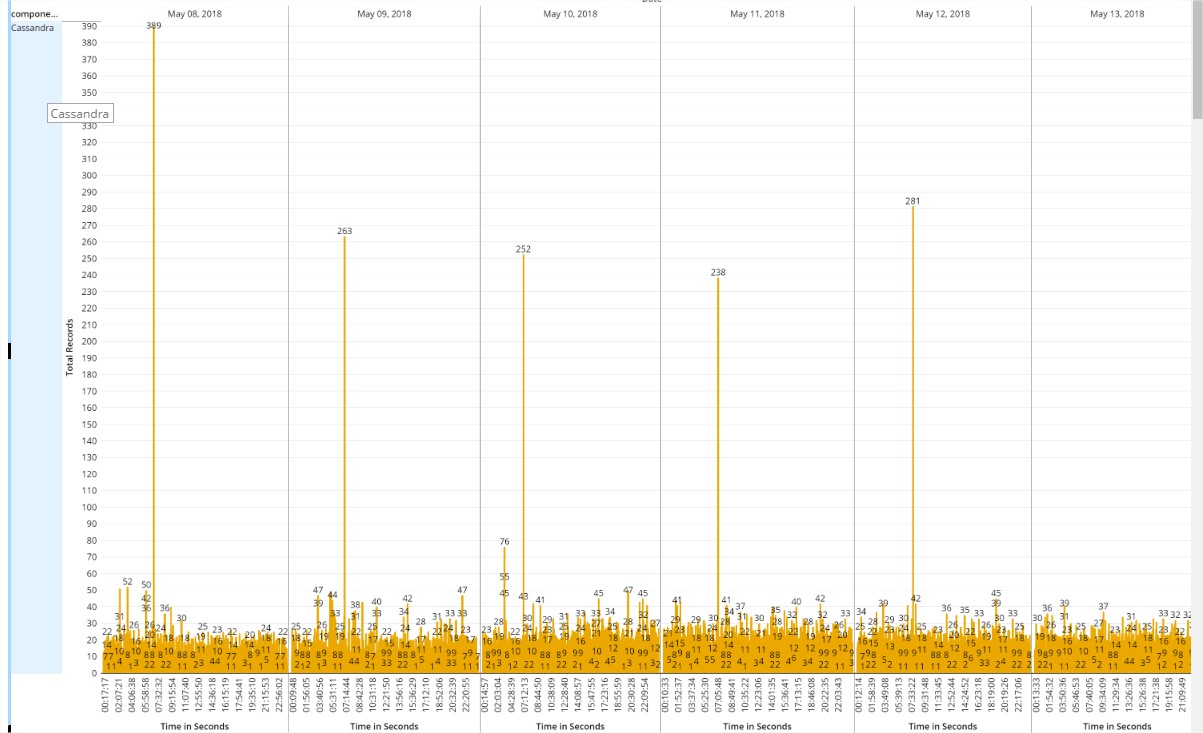
- 性能问题:显而易见,“点”越多,绘制的时间越长,性能也越差,可能等几分钟才能等到一幅图渲染完成。例如下图:如此稠密的图,展示就已经耗费很多时间,而实际上稠密的部分并无太多意义:
- 显示问题:假设所用的电脑屏幕分辨率是1920 x 1080,同时X轴以时间为单位,当展示大范围的时间范围(例如1年)的时候,则每个肉眼有价值的点是“1年*365天*24小时/1920=4.56天”,而56天的数据范围,要不全部展示(则出现问题1),要不采取一定的策略,仅展示一部分。
所以结合现实(电脑分辨率)和性能问题(数据量太大),很多metric绘制采取了一定的策略。例如上文提及中观察到奇怪现象原因在于:
当展示一段时间范围内的数据时,采用的是平均值。所以当时间范围越大,尖峰越不准确,因为这个尖峰实际上所显示时间范围的平均值。
解决:
了解现象的原因,自然可以注意到并接纳这个现象,同时也大体能思考出如何解决, 既然展示的是平均值,那真正需要“尖峰”,展示最大值即可。
(1)对于没有提供辅助方案或者懒于处理数据的用户:
接纳这个现象,真正需要尖峰数据时,多选择尖峰时刻,多缩小范围。
(2)很多metric系统提供了辅助方案:
例如Cassandra自带的opscenter中的一些图: 显示平均值之外,显示最大值和最小值:
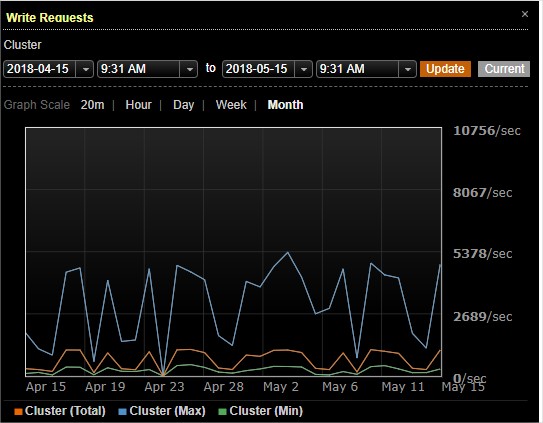
例如circonus提供了Aggregation Overlays,在原有默认展示图的基础之上,展示各种定制的“图层”
增加图层后:最大值变成了6.1,而不是最开始的0.167,时间点也不是图1所展示的尖峰时刻。
小结:
注意metric图形中是否有spike erosion现象,如果存在,则接受之并适当处理,才能获取到真正想要的数据。而不是诧异于数据的诡异。
扩展阅读(一):
下图为redis监控的一个指标,表示当前连接的客户端的数目,但是奇怪的是,偶尔会出现小数结果:例如图中的37.5.
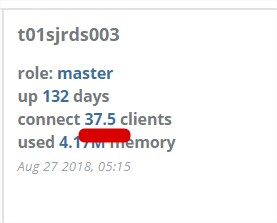
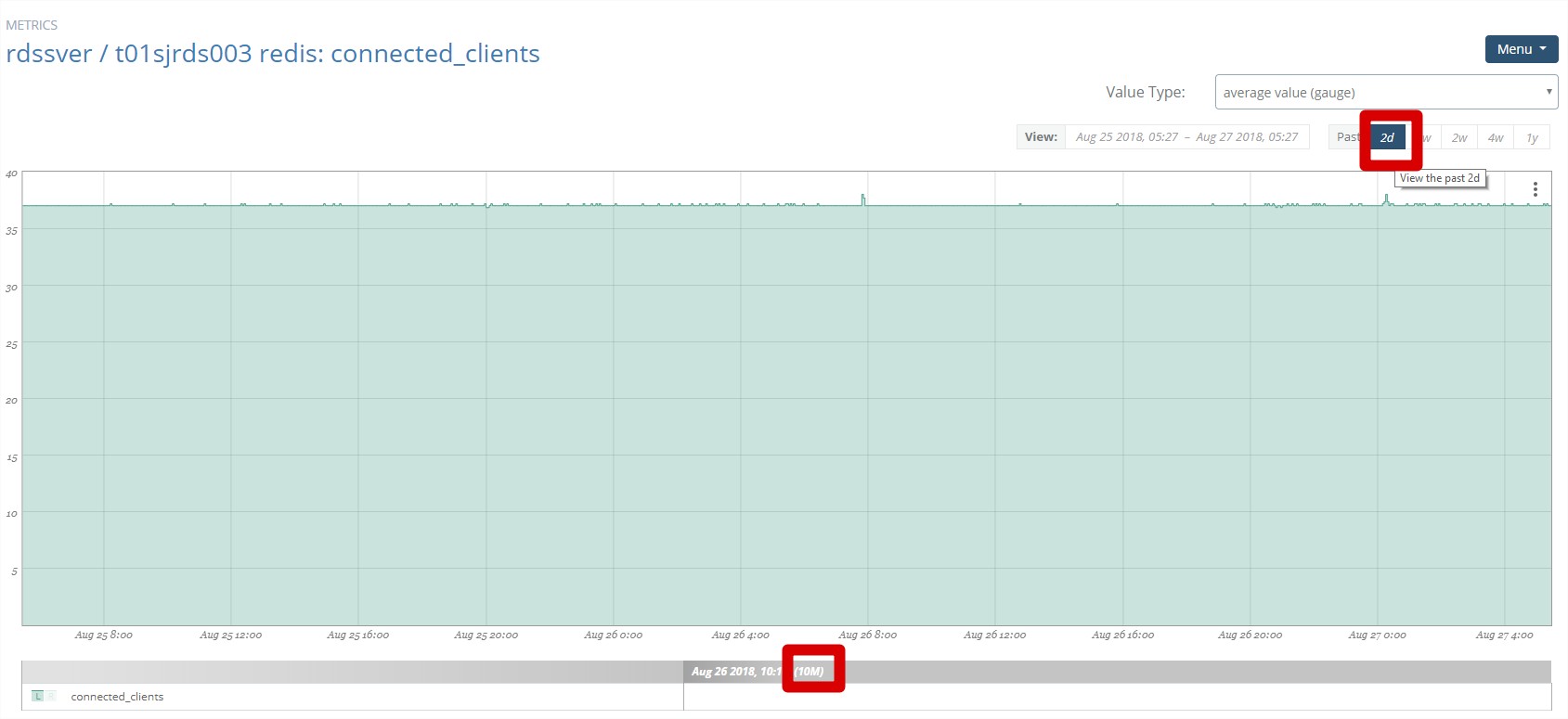
实际上,虽然是gauge的值类型,也是整型值,但是显示时间范围不同时,怎么展示值是个问题?是最后一个数据,还是第一个数据,还是平均数还是最大值,而在这里可以注意到value type是average value即平均值。例如时间范围选择2天时,会以10分钟为频度计算平均值,所以会出现小数点值。
扩展阅读(二):
选取某个时间点观察metric-core的timer的结果,结果如下图:
Timer: name=requests, count=1738812, min=0.489332, max=4.801018, mean=1.072621656614786, stddev=0.38070645373188244, median=1.02622, p75=1.2168807499999998, p95=1.6256607499999998, p98=1.9419521799999988, p99=2.557450750000006, p999=4.771496928000004, mean_rate=0.0, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/millisecond, duration_unit=milliseconds
大致得出结论:99.9%的时间小于4.77ms
但是仅仅间隔5分钟后,观察到的metric发生改变:
name=requests, count=1739530, min=0.523682, max=51.885614999999994, mean=1.1354011906614785, stddev=1.6244428387184353, median=1.0495305, p75=1.2338305, p95=1.7184529499999996, p98=1.9595656799999996, p99=2.78311552, p999=50.491461286000174, mean_rate=0.0, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/millisecond, duration_unit=milliseconds
99.9%的时间已经达到了50ms, 这里很容易产生疑问,在这么短的时间怎么会产生如此大的差距,那这样的数据是否具有可参考性?
考虑如果真的想准确统计所有的数据,则必须把所有的数据存取进去,但是metric-core基于内存实现不可能完成这种工作。所以它的实现是基于一定的统计方法来实现的。
以其中最简单的计算方法为例(com.codahale.metrics.SlidingWindowReservoir):只基于最后/新的N个数据算结果:
package com.codahale.metrics;
import static java.lang.Math.min;
/**
* A {@link Reservoir} implementation backed by a sliding window that stores the last {@code N}
* measurements.
*/
public class SlidingWindowReservoir implements Reservoir {
private final long[] measurements;
private long count;
/**
* Creates a new {@link SlidingWindowReservoir} which stores the last {@code size} measurements.
*
* @param size the number of measurements to store
*/
public SlidingWindowReservoir(int size) {
this.measurements = new long[size];
this.count = 0;
}
@Override
public synchronized int size() {
return (int) min(count, measurements.length);
}
@Override
public synchronized void update(long value) {
measurements[(int) (count++ % measurements.length)] = value;
}
@Override
public Snapshot getSnapshot() {
final long[] values = new long[size()];
for (int i = 0; i < values.length; i++) {
synchronized (this) {
values[i] = measurements[i];
}
}
return new Snapshot(values);
}
}
所以存的越多,越准确,但是实际上,不可能存太多,所以数据的准确性仅仅可以作为参考。如果要非常准确的计算,就不能采用这种基于内存的方式来统计,而是尽量拿出数据的全集。
总结:metric的阅读中,可能存在很多无法理解的现象,要考虑到实际绘制的原理和数据如何产生等问题,才能有效理解metric.