现象:
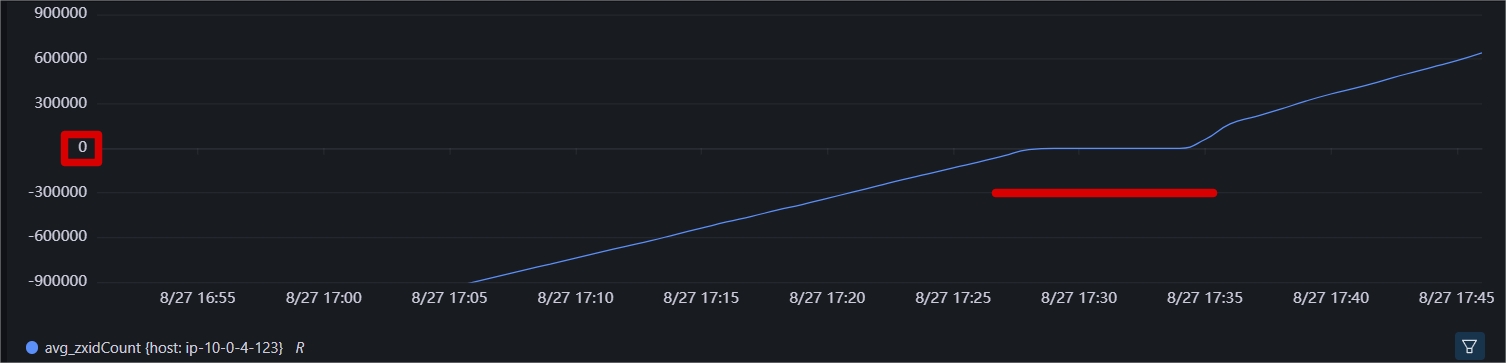
一台机器的连接数忽然降低到个位数,且不恢复。
原因:
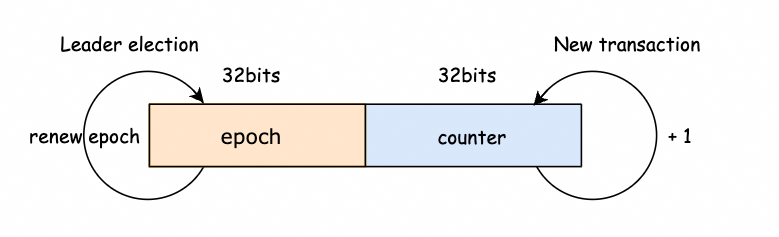
根据之前的排除经验,查看epoch指标,并没有发生变化,排除选举发生;
查看zxid没有发生变化,排除zxid。
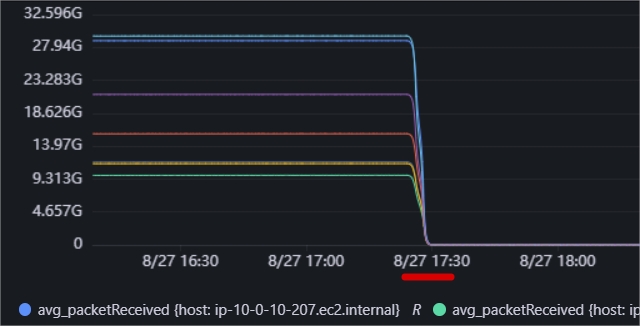
排查packetReceived指标降低为0,说明自己关闭了自己的ZooKeeperServer。
查看机器日志如下:
2023-09-01 04:02:01,662 [myid:13] - WARN [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):Follower@128] - Exception when following the leader java.net.SocketException: Connection reset at java.base/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:323) at java.base/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:350) at java.base/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:803) at java.base/java.net.Socket$SocketInputStream.read(Socket.java:966) at java.base/sun.security.ssl.SSLSocketInputRecord.read(SSLSocketInputRecord.java:478) at java.base/sun.security.ssl.SSLSocketInputRecord.readFully(SSLSocketInputRecord.java:461) at java.base/sun.security.ssl.SSLSocketInputRecord.decodeInputRecord(SSLSocketInputRecord.java:243) at java.base/sun.security.ssl.SSLSocketInputRecord.decode(SSLSocketInputRecord.java:181) at java.base/sun.security.ssl.SSLTransport.decode(SSLTransport.java:111) at java.base/sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1503) at java.base/sun.security.ssl.SSLSocketImpl.readApplicationRecord(SSLSocketImpl.java:1474) at java.base/sun.security.ssl.SSLSocketImpl$AppInputStream.read(SSLSocketImpl.java:1059) at java.base/java.io.BufferedInputStream.fill(BufferedInputStream.java:244) at java.base/java.io.BufferedInputStream.read(BufferedInputStream.java:263) at java.base/java.io.DataInputStream.readInt(DataInputStream.java:393) at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:96) at org.apache.zookeeper.server.quorum.QuorumPacket.deserialize(QuorumPacket.java:86) at org.apache.jute.BinaryInputArchive.readRecord(BinaryInputArchive.java:134) at org.apache.zookeeper.server.quorum.Learner.readPacket(Learner.java:228) at org.apache.zookeeper.server.quorum.Follower.followLeader(Follower.java:124) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:1522) 2023-09-01 04:02:01,662 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):Follower@142] - Disconnected from leader (with address: /10.14.6.56:2888). Was connected for 316796607ms. Sync state: true
很明显,出现问题的诱因是Connection reset问题,然后断开连接。第二行的日志显示它是和leader之间的连接出了问题,那么出现这种错误会如何呢?
首先,查询代码可知,能输出”Disconnected from leader”错误只能是Follower和Observer,以Follower为例:
org.apache.zookeeper.server.quorum.Follower#followLeader:
void followLeader() throws InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
ServerMetrics.getMetrics().ELECTION_TIME.add(electionTimeTaken);
LOG.info("FOLLOWING - LEADER ELECTION TOOK - {} {}",
//承担Follower角色
try {
QuorumServer leaderServer = findLeader();
try {
connectToLeader(leaderServer.addr, leaderServer.hostname);
connectionTime = System.currentTimeMillis();
//省略非核心
QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) {
//不断处理业务
readPacket(qp);
processPacket(qp);
}
} catch (Exception e) {
LOG.warn("Exception when following the leader", e);
closeSocket(); //关闭有问题的socket
}
} finally {
//省略若干代码
if (connectionTime != 0) {
long connectionDuration = System.currentTimeMillis() - connectionTime;
LOG.info(
"Disconnected from leader (with address: {}). Was connected for {}ms. Sync state: {}",
leaderAddr,
connectionDuration,
completedSync);
}
}
上面代码可以看出follower会一直处理业务请求,直到遇到错误,当遇到错误时,它会关闭连接,同时推出这个业务处理死循环,代码继续走到调用方,而调用方其实是QuorumPeer#run调用:
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;
可以看出,follower.followLeader()平时不会执行退出,但是一旦执行完走出来,就会关闭Follower。然后更新状态为looking, 重新选举:
2023-09-01 04:02:01,971 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):QuorumPeer@916] - Peer state changed: looking 2023-09-01 04:02:01,971 [myid:13] - WARN [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):QuorumPeer@1568] - PeerState set to LOOKING 2023-09-01 04:02:01,971 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):QuorumPeer@1438] - LOOKING 2023-09-01 04:02:01,971 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):FastLeaderElection@945] - New election. My id = 13, proposed zxid=0x5c10c6626f 2023-09-01 04:02:01,971 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:LOOKING; n.sid:13, n.state:LOOKING, n.leader:13, n.round:0x5de, n.peerEpoch:0x5c, n.zxid:0x5c10c6626f, message format version:0x2, n.config version:0x4e8eae578d 2023-09-01 04:02:01,972 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:LOOKING; n.sid:14, n.state:FOLLOWING, n.leader:37, n.round:0x5dd, n.peerEpoch:0x5c, n.zxid:0x5bfffffffe, message format version:0x2, n.config version:0x4e8eae578d 2023-09-01 04:02:02,020 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:LOOKING; n.sid:24, n.state:FOLLOWING, n.leader:37, n.round:0x5dd, n.peerEpoch:0x5c, n.zxid:0x5bfffffffe, message format version:0x2, n.config version:0x4e8eae578d 2023-09-01 04:02:02,021 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:LOOKING; n.sid:23, n.state:FOLLOWING, n.leader:37, n.round:0x5dd, n.peerEpoch:0x5c, n.zxid:0x5bfffffffe, message format version:0x2, n.config version:0x4e8eae578d 2023-09-01 04:02:02,049 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:LOOKING; n.sid:36, n.state:FOLLOWING, n.leader:37, n.round:0x5dc, n.peerEpoch:0x5c, n.zxid:0x5bfffffffe, message format version:0x2, n.config version:0x4e8eae578d 2023-09-01 04:02:02,070 [myid:13] - INFO [nioEventLoopGroup-7-8:NettyServerCnxn@294] - Processing conf command from /170.114.0.148:64690 2023-09-01 04:02:02,074 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:LOOKING; n.sid:37, n.state:LEADING, n.leader:37, n.round:0x5dd, n.peerEpoch:0x5c, n.zxid:0x5bfffffffe, message format version:0x2, n.config version:0x4e8eae578d 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):QuorumPeer@902] - Peer state changed: following 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):QuorumPeer@1520] - FOLLOWING 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@1306] - minSessionTimeout set to 4000 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@1315] - maxSessionTimeout set to 40000 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ResponseCache@45] - getData response cache size is initialized with value 400. 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ResponseCache@45] - getChildren response cache size is initialized with value 400. 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):RequestPathMetricsCollector@109] - zookeeper.pathStats.slotCapacity = 60 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):RequestPathMetricsCollector@110] - zookeeper.pathStats.slotDuration = 15 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):RequestPathMetricsCollector@111] - zookeeper.pathStats.maxDepth = 6 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):RequestPathMetricsCollector@112] - zookeeper.pathStats.initialDelay = 5 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):RequestPathMetricsCollector@113] - zookeeper.pathStats.delay = 5 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):RequestPathMetricsCollector@114] - zookeeper.pathStats.enabled = false 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@1542] - The max bytes for all large requests are set to 104857600 2023-09-01 04:02:02,074 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@1556] - The large request threshold is set to -1 2023-09-01 04:02:02,075 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):AuthenticationHelper@66] - zookeeper.enforce.auth.enabled = false 2023-09-01 04:02:02,075 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):AuthenticationHelper@67] - zookeeper.enforce.auth.schemes = [] 2023-09-01 04:02:02,075 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):ZooKeeperServer@361] - Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 clientPortListenBacklog -1 datadir /data/zookeeper/version-2 snapdir /data/zookeeper/version-2 2023-09-01 04:02:02,075 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):Follower@77] - FOLLOWING - LEADER ELECTION TOOK - 104 MS 2023-09-01 04:02:02,075 [myid:13] - INFO [QuorumPeer[myid=13](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):QuorumPeer@916] - Peer state changed: following - discovery 2023-09-01 04:02:02,215 [myid:13] - INFO [WorkerReceiver[myid=13]:FastLeaderElection$Messenger$WorkerReceiver@390] - Notification: my state:FOLLOWING; n.sid:35, n.state:FOLLOWING, n.leader:37, n.round:0x5dc, n.peerEpoch:0x5c, n.zxid:0x5bfffffffe, message format version:0x2, n.config version:0x4e8eae578d
通过日志中的“LEADER ELECTION TOOK – 104 MS”,可以看出,花了104ms再次重新充当了Follower。考虑到这个时间很短,影响应该很小。
再回到这个问题的原始触发点,为什么会遇到connection reset,可以查看leader上是的日志线索:
2023-09-01 04:02:01,248 [myid:37] - WARN [QuorumPeer[myid=37](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):LearnerHandler@1077] - Closing connection to peer due to transaction timeout. 2023-09-01 04:02:01,248 [myid:37] - INFO [QuorumPeer[myid=37](plain=[0:0:0:0:0:0:0:0]:2181)(secure=[0:0:0:0:0:0:0:0]:2281):LearnerHandler@1158] - Synchronously closing socket to learner 13.
通过上述日志可以看出是由于“transaction timeout”,那么这种错误指的是什么?什么时候会发生?找到代码所在地,它的位置就是LearnerHandler#ping方法?
public void ping() {
long id;
if (syncLimitCheck.check(System.nanoTime())) {
id = learnerMaster.getLastProposed();
QuorumPacket ping = new QuorumPacket(Leader.PING, id, null, null);
queuePacket(ping);
} else {
LOG.warn("Closing connection to peer due to transaction timeout.");
shutdown();
}
}
顾名思义,肯定是做健康检查的。那什么时候会ping? Leader启动后会执行Leader#lead方法,这个方法会一直持续检查follower/observer的情况,以决定是不是要断掉它们。
void lead() throws IOException, InterruptedException {
long start = Time.currentElapsedTime();
long cur = start;
long end = start + self.tickTime / 2;
while (cur < end) {
wait(end - cur);
cur = Time.currentElapsedTime();
}
startZkServer();
while (true) {
synchronized (this) {
long start = Time.currentElapsedTime();
for (LearnerHandler f : getLearners()) {
f.ping(); //ping的调用,循环去ping follower/observer
}
}
}
}
同时仔细参考上述代码,还可以看出,它是每间隔一段时间做一次。间隔时间即上述代码中的“self.tickTime / 2”,其参数可配,默认如下:
public static final int DEFAULT_TICK_TIME = 3000; protected int tickTime = DEFAULT_TICK_TIME;
那么,一旦做健康检查,它做的时机是什么?可以参考LearnerHandler.SyncLimitCheck,关键代码如下:
private class SyncLimitCheck {
private boolean started = false;
private long currentZxid = 0;
private long currentTime = 0;
private long nextZxid = 0;
private long nextTime = 0;
public synchronized void start() {
started = true;
}
public synchronized void updateProposal(long zxid, long time) {
if (!started) {
return;
}
if (currentTime == 0) {
currentTime = time;
currentZxid = zxid;
} else {
nextTime = time;
nextZxid = zxid;
}
}
public synchronized void updateAck(long zxid) {
if (currentZxid == zxid) {
currentTime = nextTime;
currentZxid = nextZxid;
nextTime = 0;
nextZxid = 0;
} else if (nextZxid == zxid) {
LOG.warn(
"ACK for 0x{} received before ACK for 0x{}",
Long.toHexString(zxid),
Long.toHexString(currentZxid));
nextTime = 0;
nextZxid = 0;
}
}
public synchronized boolean check(long time) {
if (currentTime == 0) {
return true;
} else {
long msDelay = (time - currentTime) / 1000000;
return (msDelay < learnerMaster.syncTimeout());
}
}
}
翻阅上面代码,结合之前的代码,大致可以了解到,在执行健康检查时,如果有正在做的业务,且做的业务请求如果已经在指定时间内还没有收到响应就算不健康了。如果它还没有到达超时时间,则发送一个ping请求到队列来做健康检查。如果当前根本没有业务,则也是直接发送一个ping。其中,超时时间也是配置项,不过它是必须配置的项目。
/**
* The number of ticks that can pass between sending a request and getting
* an acknowledgment
*/
protected volatile int syncLimit;/**
* The number of milliseconds of each tick
*/
protected int tickTime;
@Override
public int syncTimeout() {
return self.tickTime * self.syncLimit;
}
这里可以给出一个配置示例:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5
通过这个配置,可知,Leader每1秒做一次和Follower/Observer之间的健康检查,业务请求或者ping的响应最大超时时间为10秒。如果超过了,则leader会断开它们,然后他们遇到connection reset重新上线。
解决方案:
实际上,这种问题,通过上述的不断追问,我们已经知道,它的问题在于一个请求为什么会超过10秒没有返回。这种情况实际很多,例如主机资源使用率太高,请求量太大等,无法及时处理请求(本应用已排除这些因素),除了这点外,还有一些原因是不可控的。例如网络问题,导致的临时不可用。所以针对这个问题的解决方案是需要进一步观察,例如排查主机请求量等因素外,记录该问题发生的频率和时间以及区域特点,以做进一步明确和分析。