之前一直想把经常搞的性能测试的公共部分(压力控制部分)抽取出来作为一个公共的部分(jar),这样一方面能让开发测试者都集中在”测试性能的case”编写上,另外一个方面使用同一标准和同一实现有利于”团队”内部标准化。
实际上,现在大多直接使用jmeter来控制压力,也能达到效果,但是jmeter本身到底如何控制的,不去熟读代码很难理解,实际使用中,假设case需要调用java代码等时,还需要学习bean shell等,所以总结起来就是自由度不够大,不够透明,所以试用一段时间后,觉得不如自己实现一套,自由度大的,更广泛通用可控的,于是有了:
https://github.com/jiafu1115/performance-test-tool
直接看如何使用(基本使用方式):
compile exec:java -Dexec.mainClass="com.test.performance.PerfTool" -Dexec.args="-t com.test.performance.demo.DemoTestCaseImpl -duration 20 -thread 5 -tps 30"
(1)控制3个参数:1 持续多久 -duration 20 2 使用多少线程 -thread 5 3 TPS期待多少 -tps 30 实际使用,可以只指定线程数,让每个线程loop去发,也可以单独设置tps不设置线程数来尽量达到预期TPS.
(2)提供2种方式:1 测试Case实现类:-t com.test.performance.demo.DemoTestCaseImpl 2 收集测试结果类: -r com.test.performance.result.impl.InfluxdbCollectMethodImpl或自己提供
(3)提供3种运行信息:1 -program MyProgramName 2 -testname TestWebService 3 -runid ThisRunId
(4)提供4种case辅助: 1 before test 2 after test 3 prepare environment 4 destroy environment.
这样基本完成单机压力控制和实现,然后默认提供了influxdb的收集结果的方式和日志输出的方式可供选择,从而使用者只需要专注用例实现和结果收集即可。
结合这个单机的压力控制,还要完成三件事情:
(1) 并发控制: 可以采用jenkins的multi config项目来控制多个机器并发。
效果图:

(2) 结果收集: 可以采用influxdb等来收集,同时需要收集被测试机器的性能,可以在机器上部署collectd,然后发到influxdb,这样数据结果包含2个部分:性能测试数据和系统性能。
(3) 结果分析: 可以直接使用grafana来展示即可,而对于server的数据收集可采用collectd + grafana.
效果图:
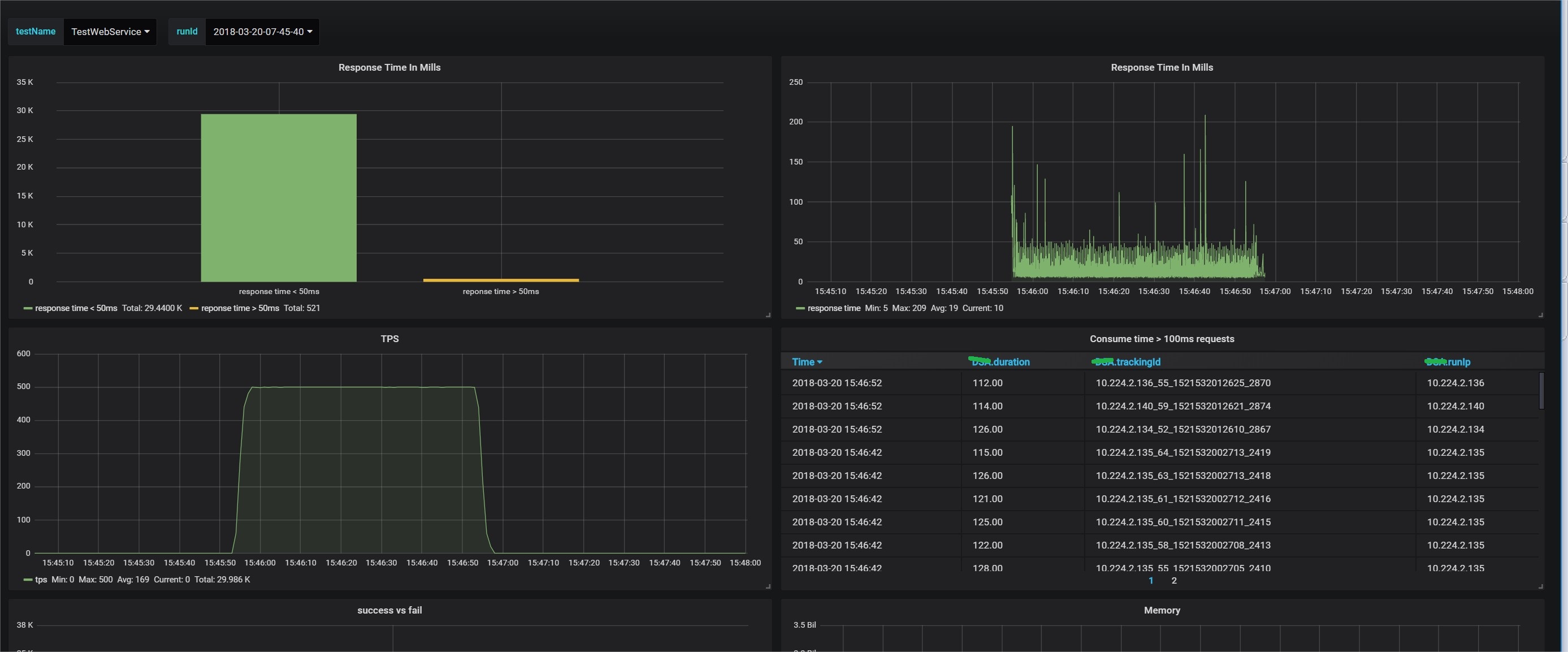
结果应该至少提供3个维度:
(1)测试的性能数据, TPS, 响应时间(分布), 成功率
(2)被测机器的系统性能: cpu, memory, io, etc
(3)被测应用的性能数据: TPS, 响应时间(分布),成功率
总结: 经过剥离变化,就解决了共同的问题,然后使得性能测试者只关注自身测试用例和测试结果的收集和展示,这样就轻松了许多。
附:
1 使用的组件的安装:
1.1 influxdb 安装:
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.5.0.x86_64.rpm sudo yum localinstall influxdb-1.5.0.x86_64.rpm service influxdb start
1.1版本后无web界面了,别找了。
1.2 grafana 安装
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.0.3-1.x86_64.rpm sudo yum localinstall grafana-5.0.3-1.x86_64.rpm service grafana-server start
1.3 collectd 安装
wget http://mirrors.163.com/.help/CentOS6-Base-163.repo yum install epel-release yum install collectd service collectd start
2. 使用的组件的配置:
2.1 influxdb + collectd收集系统信息需要的配置:
influxdb配置:
开启collectd数据收集:
[[collectd]]
enabled = true
bind-address = ":25826"
database = "collectd"
启动会报错: /usr/share/collectd/types.db
所以influx上也要装上collectd可以解决这个问题。
2.2 collectd配置: server指向influxdb
Hostname "10.224.82.92" Interval 2 ReadThreads 5 LoadPlugin cpu LoadPlugin load LoadPlugin memory LoadPlugin swap LoadPlugin battery LoadPlugin network <Plugin "network"> Server "10.224.2.147" "25826" </Plugin>